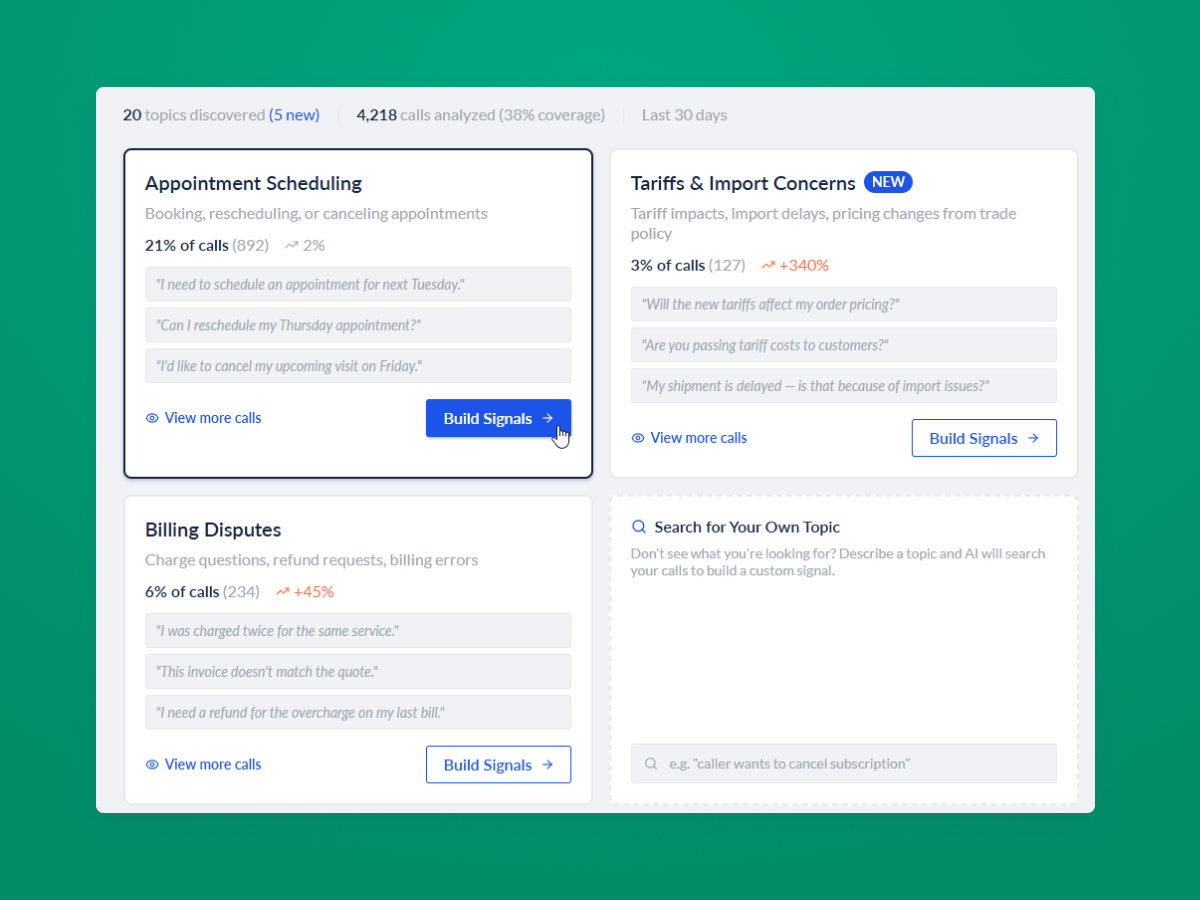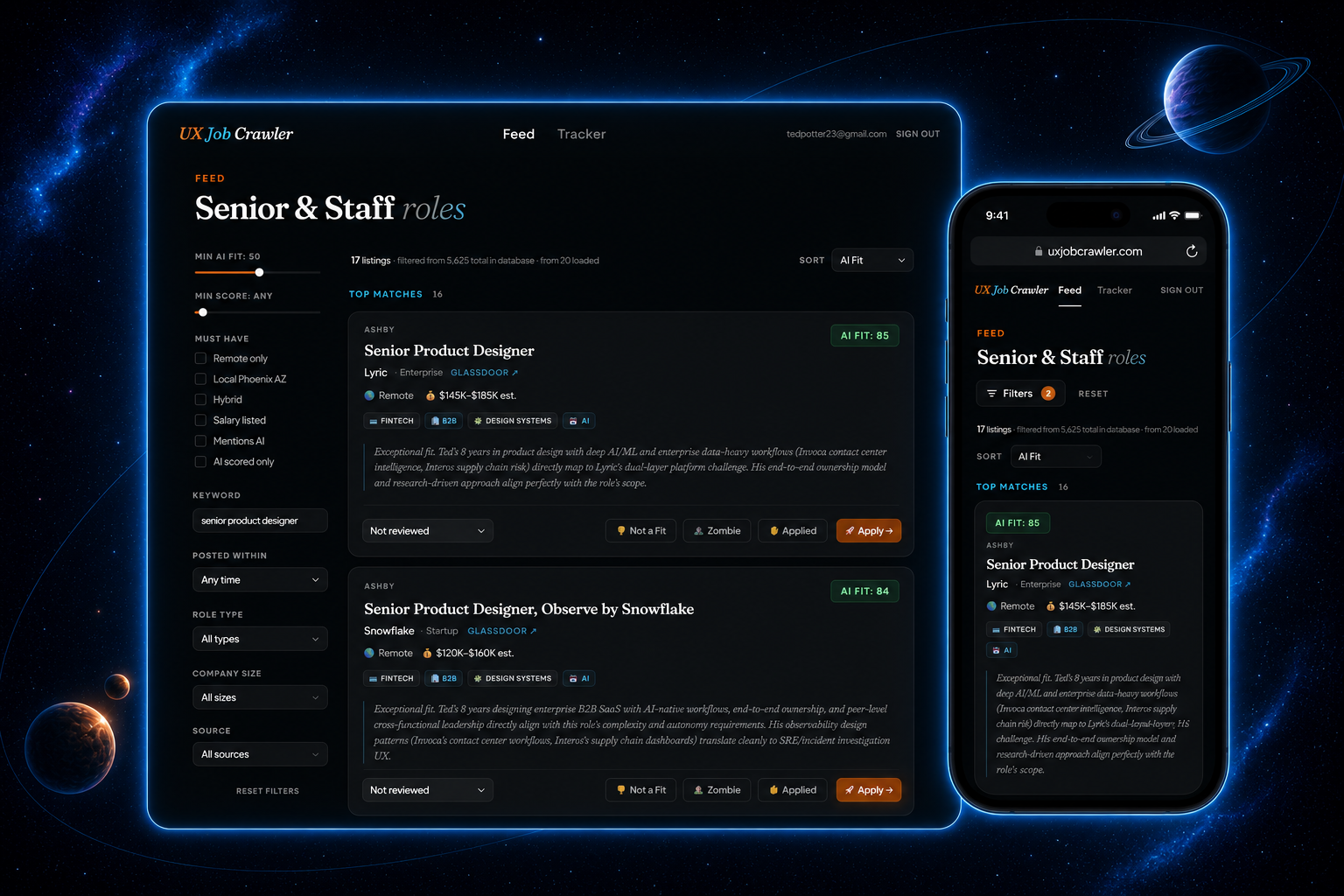
I went looking for a UX role in one of the roughest tech markets in years. The obvious move was to open LinkedIn every morning and start scrolling. Instead I asked a different question: I'm a product designer who works on AI products all day. Could I build my own?
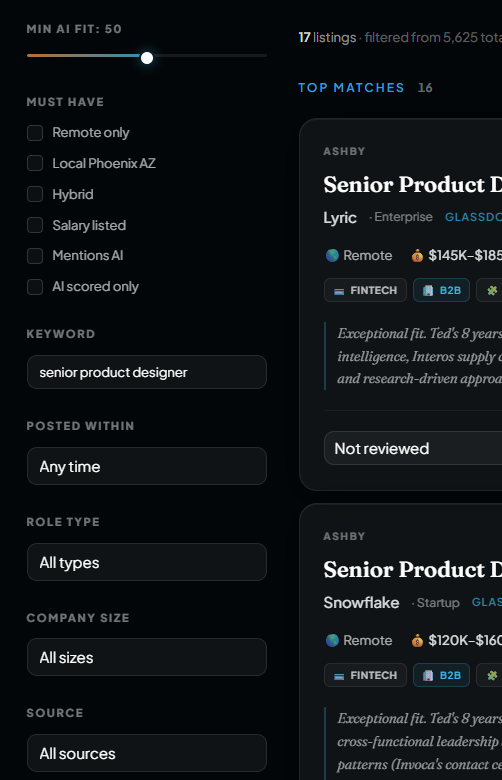
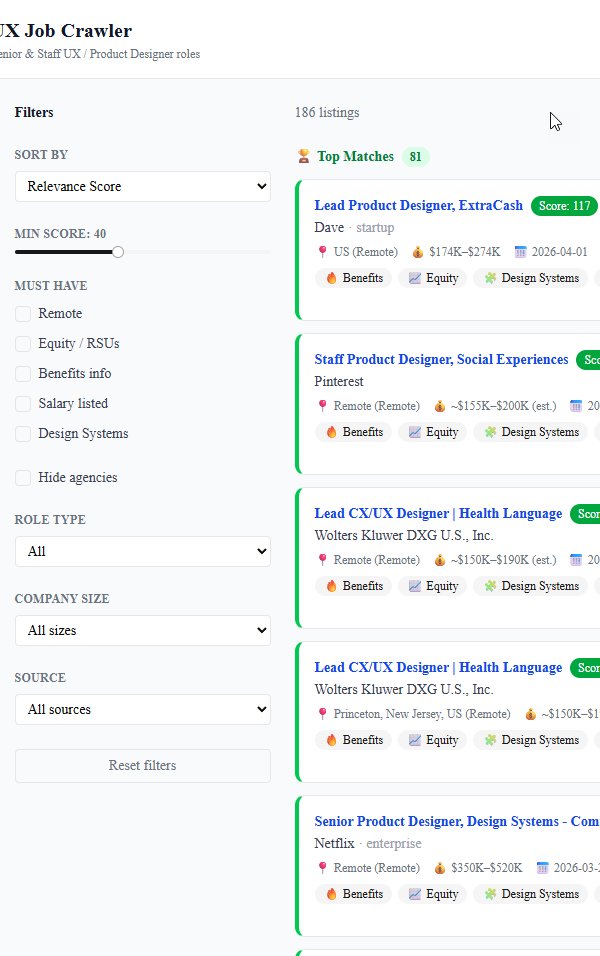
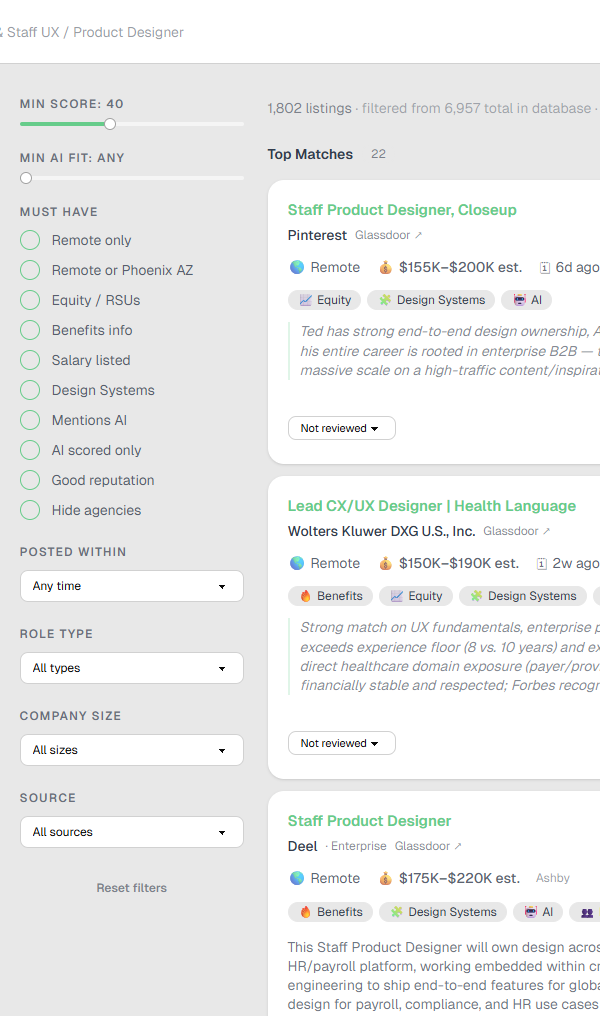
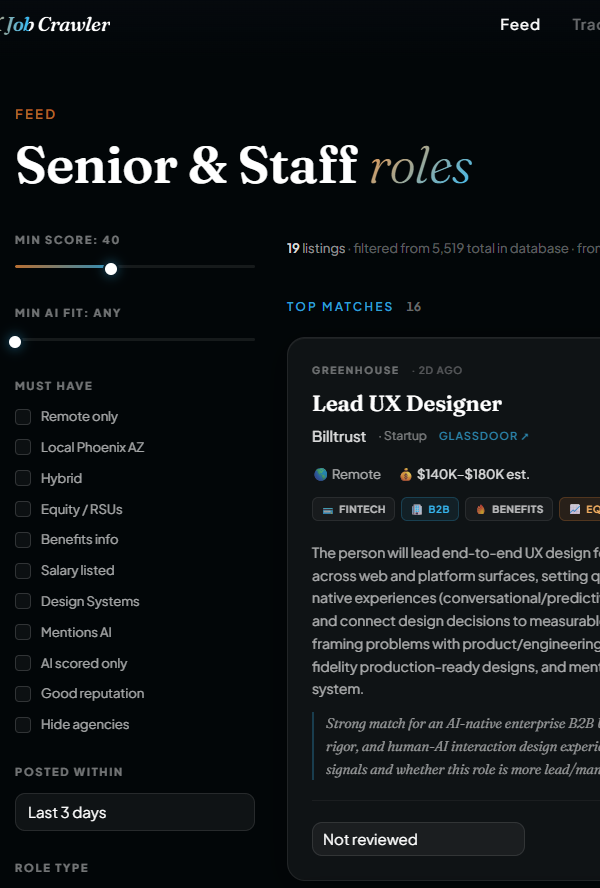
So I did. The Job Search Crawler kicks off every morning at 8am, takes around twenty minutes to scan more than a dozen job sources, scores every role against my actual experience, and emails me a ranked, AI-evaluated shortlist. I designed it, specced it, and built it solo, using a stack of APIs and tools I had never touched before. AI wrote most of the code. I made the decisions.